
When writing a bot for Instagram, using a stack of technologies selenium Webdriver, Java, XPath, encountered a problem.
Instagram is now trying to protect themselves from bots, so to disassemble it most interesting.
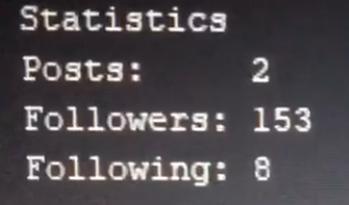
The task arose, to get the number of Posts, Followers, the Following on the user’s open profile.
This is what the HTML block code looks like, which contains this data in Instagram:
<ul class=" _3dEHb">
<li class=" LH36I">
<span class=" _81NM2">
<span class="g47SY lOXF2">
3
</span>
posts
</span>
</li>
<li class=" LH36I">
<a class=" _81NM2" href="/username/followers/">
<span class="g47SY lOXF2" title="153">
153
</span>
followers
</a>
</li>
<li class=" LH36I">
<a class=" _81NM2" href="/username/following/">
Following:
<span class="g47SY lOXF2">
8
</span>
</a>
</li>
</ul>
In total, we have three digits, which are represented in different ways, we use this code to get the data:
String posts=driver.findElement(By.xpath("//ul/li/span/span")).getText();
String followers=driver.findElement(By.xpath("//a[contains(@href,'followers')][1]//span")).getAttribute("title");
String following=driver.findElement(By.xpath("//a[contains(@href,'following')][1]//span")).getText();
System.out.println("Posts: "+posts);
System.out.println("Followers: "+followers);
System.out.println("Following: "+following);
In order to get the number of posts:
<ul class=" _3dEHb">
<li class=" LH36I">
<span class=" _81NM2">
<span class="g47SY lOXF2">
3
.........
We use the XPath design://ul/li/span/span
We simply list the last nesting of the tree and as a result we get the contents-“3”
Next we will know the number of subscriptions:
.........
<a class=" _81NM2" href="/username/followers/">
<span class="g47SY lOXF2" title="153">
153
</span>
followers
.........
//a[contains(@href,’followers’)][1]//span here we find the first encountered tag A, in href link of which, there is a substring followers, and take from it attributes of the span tag. The title attribute contains the number of subscribers. In the example, this number is 153.
Finally, we get the number of subscriptions:
.........
<a class=" _81NM2" href="/username/following/">
Подписки:
<span class="g47SY lOXF2">
8
.........
//a[contains(@href,’following’)][1]//span the same as in the second command, only the reference is searched for the occurrence of the following, and we are interested not the attribute, but the text, in this case 8.
The task was interesting, in the selection of the correct combination of XPath helped me online editors of XPath, none of them was not comfortable enough, so I can not recommend any one, but with them you can play with the XPath on a lot faster than Progonaya Options through the bot.